
ECOC 2025 技術焦點:OIF 談 AI 應用中的能效需求與多重挑戰
- 2025年10月1日
- 讀畢需時 2 分鐘
前言
AI 訓練與推理的爆炸式成長推動了資料中心網路的快速演進。無論是機櫃內的 Scale-Up,還是跨機櫃的 Scale-Out,光學與電氣互連的設計都面臨 距離、延遲、可靠性與能效的多重要求。
OIF 作為跨產業標準化組織,集合了超過 160 家成員公司,致力於推動 互通性、能效標準與架構協調。在 ECOC 2025 上,OIF 分享了 AI 網路中的 能效需求分析,並探討了 CPO、CPC 與不同連結架構的取捨。
內容
1. AI Compute Pod 架構中的連結類型
OIF 將 AI Pod 中的連結分為五類:
Compute I/O(如 PCIe、CXL、UCI)
Memory Interface(如 HBM, CXL over PCIe)
Scale-Up(GPU/加速器內部連結,需低延遲)
Scale-Out(跨 Pod 連結,需更長距離)
Front-End Ethernet(連接資料中心外部網路)
👉 這次重點放在 3. Scale-Up 與 4. Scale-Out,因為它們是 AI 計算最關鍵、也是能耗與延遲挑戰最嚴峻的部分。
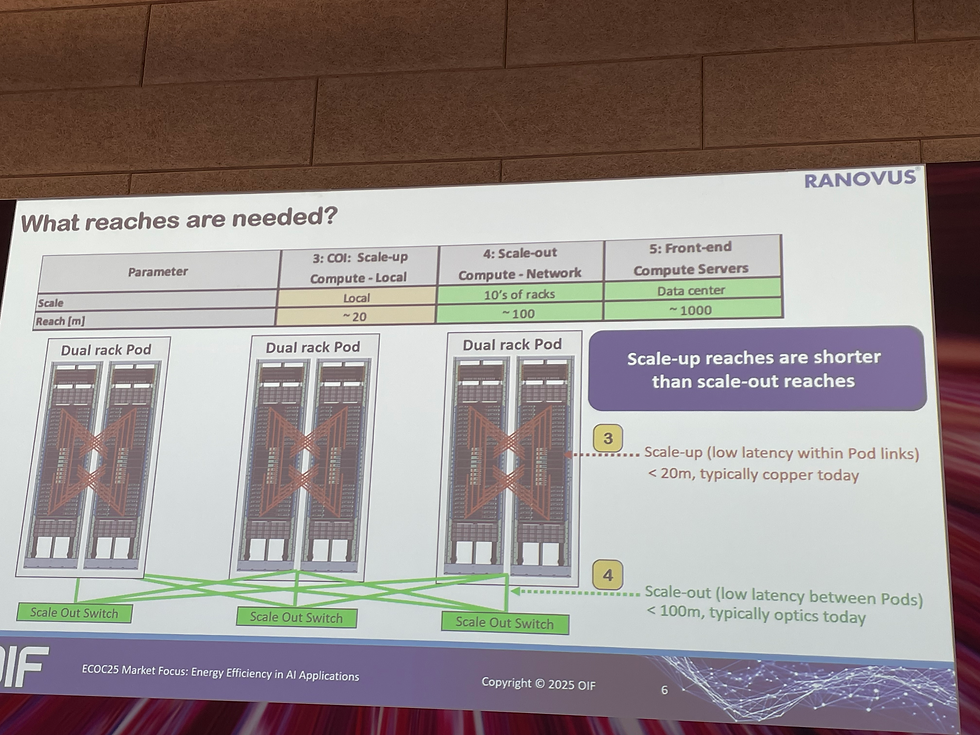
2. 距離需求
Scale-Up:目前多在單一機櫃內,主要用銅纜。但下一代 AI 叢集需橫跨多個機櫃,要求 ~20 m reach。
Scale-Out:跨 Pod 的連結,距離需求達 ~100 m,傳統銅纜難以滿足,需光學介入。
3. 延遲與 AI 負載特性
AI 計算依賴 矩陣分塊 (tiling),每個加速器需完成部分任務後再彙總。
若部分鏈路延遲過高,整體 GPU 效率下降。
延遲來源:
傳輸時間 (propagation delay)
錯誤檢測與重傳 (retransmission delay)
解法:需極低 bit error rate (BER) 與高效的 FEC 機制。
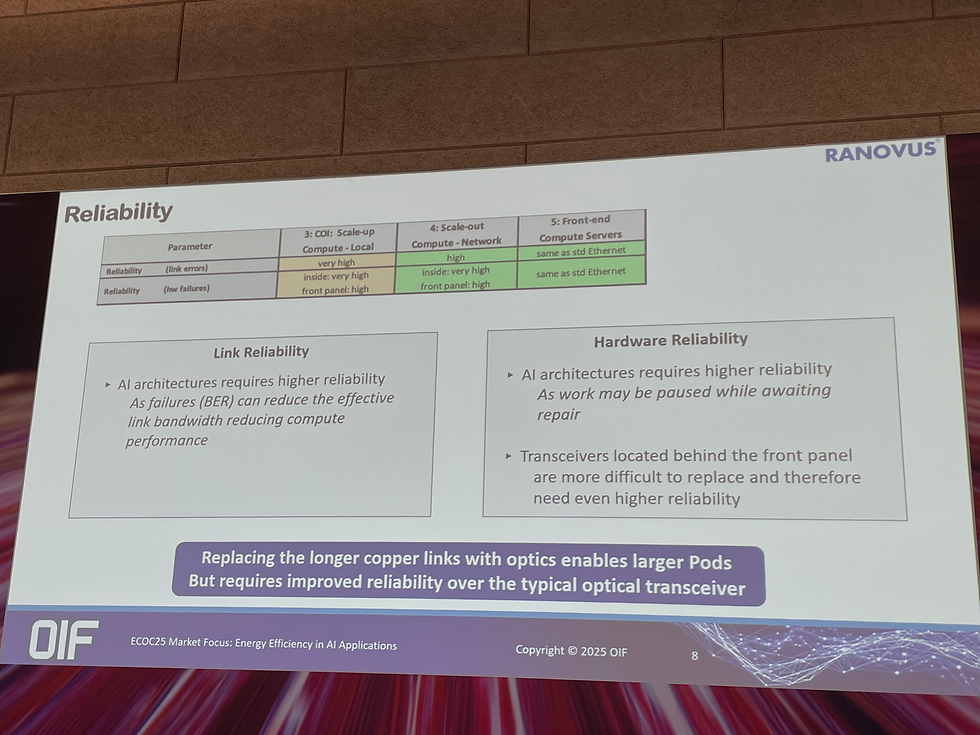
4. 可靠性需求
鏈路可靠性:需保證低錯誤率,避免頻繁重傳。
硬體可靠性:若 GPU 或鏈路故障,需重新 checkpoint,導致訓練效率大幅下降。
Pluggable vs. CPO:
前面板 (pluggable):易於維護,但可靠性需求更高。
內部封裝 (CPO):銅走線短、可靠性佳,但維護不便。
5. 頻寬密度與能效目標
Hyperscaler 要求:
>2 Tbps/mm shoreline density。
<4 pJ/bit 能耗。
設計取捨:
CPO:銅走線最短,頻寬密度與能效最佳。
CPC (Co-Packaged Copper):介於 Pluggable 與 CPO 之間。
Pluggable:靈活,但銅走線長、損耗高。
👉 OIF 繪製的能效地圖顯示:CPO 在 <4 pJ/bit 與高密度區域最有潛力,但落地需克服製造與維護挑戰。
總結
OIF 在 ECOC 2025 的分析凸顯:
AI 網路對距離、延遲與可靠性提出更嚴苛需求,傳統銅纜逐漸被光學取代。
Scale-Up (20 m) 與 Scale-Out (100 m) 是未來能效設計的重點場景。
延遲與 BER 密切相關:需透過更低錯誤率與高效 FEC 控制尾延遲。
可靠性成為 AI 效率關鍵:MTBF 必須大幅提升,避免 checkpoint rollback。
CPO 能效最佳,但非唯一解:Pluggable、CPC、CPO 將依應用並存。
整體而言,OIF 的訊息是:AI 工廠需要新的能效標準與系統級設計哲學。不僅是速率升級,而是 在能效、可靠性與可擴展性之間找到平衡,這將決定未來 AI 網路的成敗。














留言