
2025 OCP APAC Summit | Scale-up for AI: Balancing Compute, Memory and Networking|Broadcom
- 2025年8月5日
- 讀畢需時 3 分鐘
摘要
Broadcom 在最新2025 OCP APAC Summit 中提出 Ethernet 為核心的 Scale-up 與 Scale-out 解決方案,用於建構超大規模 AI 訓練叢集。透過 100 Tbps Tomahawk Ultra 交換晶片與 AI Fabric Router,支援從單機架擴展至跨數據中心的分散式運算,實現 <400 ns 低延遲、200,000+ GPU 集群、跨 100 km 連結。此開放標準將推動下一代 AI 基礎架構邁向更高效能、更低功耗與更簡單拓撲的未來。

內容
1. 背景與挑戰
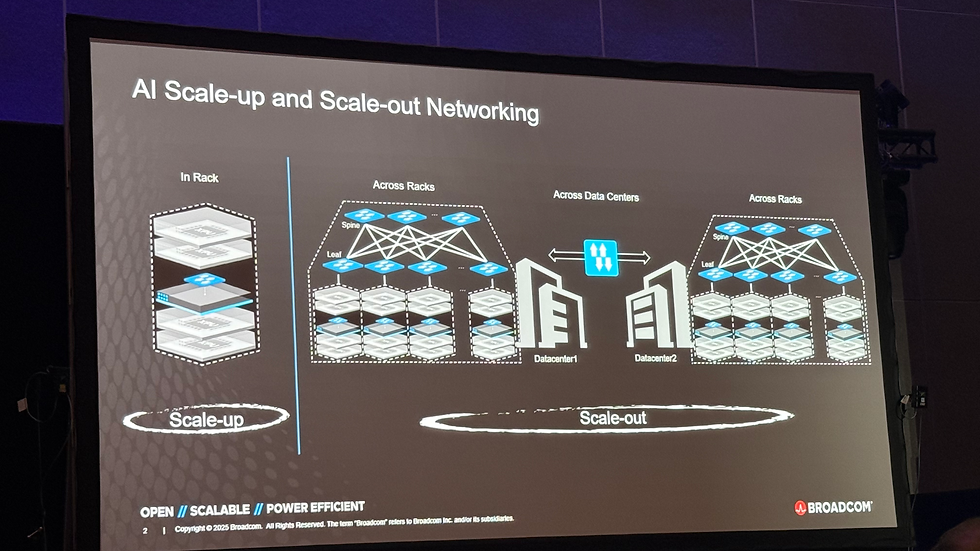
AI 訓練模型的規模呈指數成長,單一機架已無法容納所有運算資源。當運算需求擴展至數百甚至數千 GPU/XPUs 時,系統必須從 機架內擴展(Scale-up) 進一步進入 跨機架與跨數據中心擴展(Scale-out)。此過程對網路的需求變得前所未有地嚴苛:
高頻寬:HPM 與 XPU 間頻寬已達 40–100 Tbps
低延遲:資料交換需在數百奈秒內完成
高可靠性:減少封包錯誤與重傳
能效與擴展性:降低光學與銅纜成本,同時支持更大規模叢集



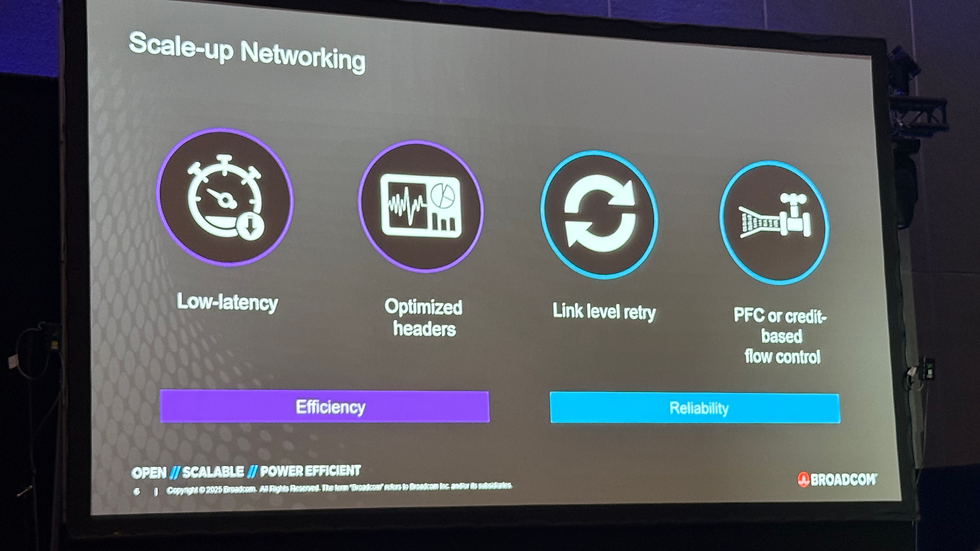
2. Scale-up 網路的核心要素
2.1 當前瓶頸
銅製背板距離有限,限制單域內 XPU 數量(目前 <100)
現有交換機 Radix 與頻寬不足
隨著 GPU/HPM 接口提升至 100 Tbps,現有拓撲難以支撐
2.2 Broadcom 解決方案
Ethernet 為基礎的 Scale-up (SU) 架構:
開放標準,OCP 社群共同制定
從 XPU 經以太交換機往返延遲 <400 ns
其中交換機延遲僅 250 ns,其餘 150 ns 來自上下堆疊傳輸

Tomahawk Ultra 交換晶片:
50 Tbps 頻寬,250 ns 延遲
支援未來 100 Tbps 版本,減少光纖需求並簡化網路層級

3. 從 Scale-up 到 Scale-out
3.1 內部 Scale-out(數據中心內)
未來單數據中心可容納 128,000–200,000 GPUs
使用 100 Tbps 交換機 可由兩層拓撲實現更簡單網路:
光模組需求減少 67%
延遲降低
可靠性提升(較少光纖連結與中繼)


3.2 跨數據中心 Scale-out
為達百萬 GPU 集群,需連接多個 50–60 MW 數據中心
Broadcom 推出 AI Fabric Router:
支援跨 60–100 km 連結
深度緩衝設計,多晶片堆疊,內建 HBM
線速加密,確保跨站點資料安全

4. Ethernet 的戰略地位
Broadcom 強調 Ethernet 的普及性、開放性與經濟性:
多廠商可相容
不受專利或授權限制
成本相對專有協議(如 NVLink)低
可持續透過 OCP 社群擴展與優化
5. 技術趨勢與未來發展
介面速率將從 100G SerDes 過渡至 200G、400G
網路拓撲將由 三層縮減至兩層,降低延遲與功耗
光學取代銅纜成為主流,推動超大規模運算擴展
跨數據中心的整合帶來 AI 超級叢集 新形態
結論
Broadcom 以 Ethernet 為核心的 Scale-up/Scale-out 解決方案,成功在低延遲與高頻寬間取得平衡,滿足下一代 AI 超級運算叢集的需求。其開放標準及與 OCP 社群的協作,將推動產業加速從機架內運算邁向跨數據中心的全球分散式 AI 平台。
核心價值包括:
延遲低於 400 ns 的網路互連
100 Tbps 級交換晶片簡化拓撲
支援 200,000+ GPU 集群與跨 100 km 連結
開放標準與產業協作的長期可持續性
未來幾年,隨著 SerDes 升級與光學技術普及,Ethernet 將成為超大規模 AI 訓練的主流互連技術,並帶動整個資料中心架構的革新。

留言