
Apollo/Lightwave Fabrics:Google 用 OCS 重寫資料中心網路的那一刀
- 2025年10月16日
- 讀畢需時 8 分鐘
前言
在資料中心網路(DCN)這個世界裡,**Clos + 電子封包交換(EPS)**曾經是唯一解。直到 AI/ML 集群成為主流、東西向流量暴增、以及每一代升速都把功耗和成本往上推,過去那套“堆更多電子交換晶片、拉更多銅纜與跳線”的方法,開始顯得笨重又昂貴。
Google 的 Apollo/Lightwave Fabrics 做了一個關鍵選擇:把**(Optical Circuit Switching, OCS)**真正放進生產網路,讓「可重構拓撲」成為日常操作,而不是實驗室 demo。這不是把 EPS 丟掉,而是用 OCS + SDN 控制 + WDM 光模組演進,重新切分哪一段在光域完成、哪一段在電域處理,讓網路升級與擴容回到符合經濟性與工程邏輯的軌道上。
接下來,我用工程管理+產品視角,完整拆解這條路徑:發展歷史 → 架構與硬體 → 控制與可重構 → 效益數據 → ML 應用 → 風險與下一步。
內容
一、發展歷史(Timeline):從想法到生產規模
SIGCOMM 2022《Jupiter Evolving》
關鍵轉折:把 Jupiter 從 Clos 轉成 direct-connect 拓撲,間層用 MEMS OCS 組成 DCNI(Datacenter Interconnection Layer),讓拓撲重構與增量升級成為日常流程,而不是一次性大改造。
對外公布的量化成果:速度/容量 ×5、CapEx −30%、功耗 −41%,而且在真實流量下達成;OCS 重構速度比過去 patch-panel 流程快 3×;實際營運中 60% 流量走直達路徑、平均僅 1.4 個 block hop。
意義:證明 OCS + SDN 能替代傳統 spine 層,保留高產能、同時給升級與運維留出口。(Google 研究頁面摘要亦佐證上述數據與方法論。)
2022《Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale》
第一份系統級白皮書:把 3D-MEMS Palomar OCS、循環器(circulator)做雙向、以及多世代 WDM 模組共存的設計動機與折衷,完整公開。
關鍵句:用 circulator 讓單纖「全雙工」,等效把 OCS radix 翻倍;並詳述為此帶來的 MPI/RIN/回波干擾處理與規格要求。
OFC 2023《Apollo:Large-Scale Deployment of OCS》
把硬體細節與量產經驗放在主舞台:
Palomar OCS:136×136 非阻塞、插入損耗 < 2 dB、典型回波 ≈ −46 dB(規格 < −38 dB)、整機最大 108 W。
WDM 光模組演進:從 40G QSFP+ → 800G OSFP 的成本與能效曲線;以 DSP-based PAM4 與 OIM(Optical Interference Mitigation) 對抗 circulator 雙向路徑引入的干擾。
三大能力:Topology Engineering、Fabric Expansion、Rapid Tech Refresh(多代模組/ASIC 共存)。
SIGCOMM 2023《Lightwave Fabrics》
把 OCS 概念抽象化為 Lightwave Fabric,直接服務 Datacenter + ML 兩種場景;針對 TPU v4 等超大集群,依通訊模式重構拓撲,用更短平均路徑與更高有效吞吐,去對應長壽命的 elephant flow。
Google Cloud Blog(Jupiter 系列)
以產品觀點總結:在生產網路中,Flow Completion Time 約 −10%、Throughput 約 +30%、功耗約 −40%、成本約 −30%;同時能做到線上重構與異質速率共存,避免“升級要大修”的老問題。 Google Cloud
2024 年再度對外回顧 Jupiter 世代演進(第 5 代 Jupiter 雙向 13 Pb/s bisection),顯示同一路線仍在擴張。
科普說明:
想像資料中心就像一個巨大城市的道路網。過去的「Clos 架構」是很多高速公路交錯在一起,車流靠紅綠燈(電子交換器)來分配。但隨著 AI 流量暴增,光靠紅綠燈控制,越來越塞車、越耗電。
Google 從 2022 年開始,推出Apollo專案,把「光路」這條高速快車道引進來,直接讓大卡車(AI 訓練這種超大流量)走專屬通道,不用跟小車(短流量)擠。這一路從研究(Mission Apollo)→ 部署(SIGCOMM 2022, OFC 2023)→ ML 應用(Lightwave Fabrics),像是把一個實驗室技術逐步推成日常基礎建設。

二、架構總覽:Clos → Direct-Connect(OCS+SDN+WDM)
核心設計是把“spine 的交換功能”抽走,改由 OCS(光交叉連接)提供AB(Aggregation Block)之間的光路,再用 SDN 控制平面(Google 內部稱 Orion)做流量工程(TE)與拓撲工程(ToE)。
DCNI 層:用多台 3D-MEMS OCS 構成的光交換間層,提供程式化 restriping與邏輯拓撲重構。
循環器雙向:每條光路走單纖、全雙工,把 OCS 端口效益最大化,但要求嚴格回波與 OIM 機制,所以收發器端採 DSP-PAM4 + 數位補償。
WDM+多代共存:OCS/纖芯/循環器對速率與波長高度透明,因此可以讓 40G/100G/200G/400G/800G 模組在同一條“光骨幹”上過渡升級,把最貴的那一段(光被動與 OCS)攤平折舊。
直白說:越往內核越「光域」、越往邊緣越「電域」。光域負責節點間「通道」的快速重組,電域負責封包層的「排程/緩衝/隊列」。這個切分,讓升級節奏與工程複雜度都回到可控。
科普說明:
傳統做法:每個小區(機架)都要經過「市中心」才能到另一個小區。這會造成「繞遠路」。Apollo 的做法:把中間的紅綠燈(spine 交換器)換成光學十字路口(OCS),可以直接重劃「哪兩個小區直接有光纖高速路」。這樣一來,長時間、流量大的傳輸就不用繞路,效率更高。而且,光纖不像電子晶片那樣需要大量耗電降溫,更環保。
三、硬體層:Palomar OCS、WDM 與鏈路工程
Palomar OCS(3D-MEMS)
結構:2D 光纖陣列+2D 透鏡陣列+雙 MEMS 鏡面;每條業務光走兩面鏡子形成任意對接;OCS 寬頻且互易,可任意 N×N 映射。
效能:136×136、IL < 2 dB、典型 RL ≈ −46 dB、最大 108 W、大規模量產部署(數以萬計端口)。
控制:相機回授監測 850 nm monitoring 光,降低每鏡獨立感測的 BOM 與複雜度(這點對量產可維護性很關鍵)。
WDM 與收發器(OIM/DSP)
演進:40G QSFP+ → 800G OSFP,20× 帶寬,同時能效與單位成本下降(以 datacom 場景優化)。
OIM:circulator 雙向帶來 MPI/內插回波/串擾,以高 ER 要求、RIN 管控,再配合DSP-PAM4算法做抵消/均衡。
鏈路預算:OCS + circulator 額外損耗 → 以 高功率 DML、低損 mux/demux 封裝、FEC 與 DSP 調整補回。
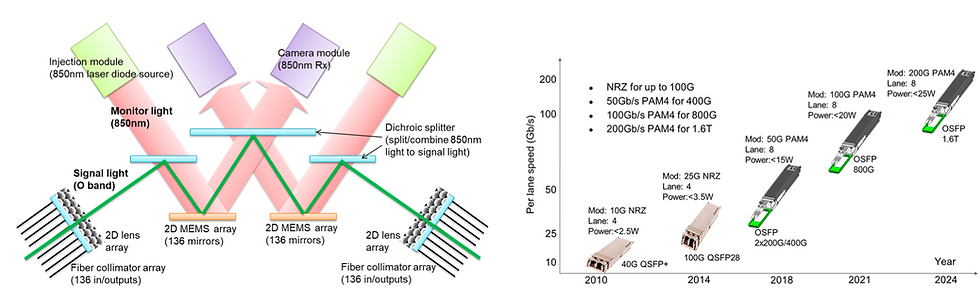
科普說明:
Palomar OCS就像一面巨大的「魔鏡陣列」,每個小鏡子都能傾斜,把光束反射到指定的出口。這就像一個光的「迷宮路口管理員」,能在幾毫秒內把光路調到新方向。**WDM(波分複用)**則像高速公路的多車道,一條纖維同時跑好多種顏色的光,每種顏色代表一條車道。這讓舊的 40G、100G、400G 模組都能共用同一條纖維,等於高速路不用重建,就能跑更多車。
四、控制與可重構:TE + ToE 的雙層優化
Orion(SDN)*把 Jupiter 拆成多個控制領域:
域內(RE):AB 內部路由與對外介面;
域間(DCNI):把 OCS 分成四個失效域(25%/域)與多層因式分解的拓撲映射,避免單點爆炸半徑,並把每次重構的差異最小化(同時最小化需要 drain 的容量)。
兩層優化目標:
TE(Traffic Engineering):在既定拓撲上做 WCMP/負載分拆,在**直達(stretch=1)與間接(stretch=2)**之間找平衡;短流敏感時優先直達,長流則以容量為導向。
ToE(Topology Engineering):動態改變直連邊數量與對象,匹配流量矩陣與異速/異徑 block;支援在線增量擴容(1/8→1/4→1/2→full DCNI)。
結果:實務上 60% 流量可直達、平均 block-level path 1.4 hop,在吞吐與尾延遲(FCT)間給出更好的折衷;OCS 重構流程比舊法快 3×,對維運團隊很友善。
科普說明:
如果 OCS 是「會變形的光纖道路」,那 SDN 控制器(Orion) 就是交通指揮中心。
TE(流量工程):像即時導航(Google Maps),決定哪條路分流比較快。
ToE(拓撲工程):像城市規劃師,會在需求改變時,把道路結構重新規劃,例如新增直達快速道路。
這兩個互相搭配,讓整個網路像是一個可以「隨需求改造」的城市。
五、量化效益與營運觀察
硬數據(Google 公開):FCT −10%、Throughput +30%、功耗 −40%、CapEx −30%;可在不中斷升級下持續演進,替代“搬機房級”的 spine 更新。
工程面好處:
把最貴的層(光域)做成耐久資產,用 WDM/OCS 攤長生命週期;
升級彈性:AB 可異速共存,避免“慢速 spine 掐住快 AB”;
運維單位操作風險下降:拓撲重構流程化、可預測;
AI/ML 友善:可針對既知的 all-to-all/多階段交換型通信,先配置拓撲再丟 workload。
科普說明:
從公開數據來看,Apollo 帶來的效果相當驚人:
傳輸完成時間縮短約 10%(小車不會被大卡車擠壓)。
總吞吐量提升約 30%(道路更順暢)。
功耗降低 40%(少了很多耗電的電子紅綠燈)。
成本下降 30%(光纖基礎設施能用更久)。
這些數字不是模擬,而是來自 Google 真正在跑的資料中心。對一家需要每天處理全球搜尋、YouTube、雲端運算的公司來說,這些節省就是巨大的差異。



六、在 ML/TPU 叢集的落地:Lightwave Fabrics
場景:TPU v4 Pod 等上千~上萬加速器的訓練叢集,流量模式長壽命、可預測、階段性。
方法:把 Fabric 當作“可編排的光層”,在每個訓練階段前把直連矩陣調成最合適的形狀,縮短平均路徑、降低擁塞,等效提升算力密度。
意義:這種“先配路、後運算”的思維,讓網路不再只是被動承載,而是與工作負載共同設計。
科普說明:
AI 訓練不像一般小資料傳輸,它更像是「成千上萬台卡車要同時彼此交換貨物」。
如果還是用舊的道路設計,大家都會塞在市中心。但透過 OCS,Google 可以在每個訓練階段開始前,重劃道路拓撲,讓這些卡車有專用直達高速路。這就是Lightwave Fabrics的核心:讓 AI 訓練不再受限於網路瓶頸。Google 的TPU v4 Pod(數千顆 AI 晶片)就是靠這樣的網路設計,達到 exaflop 級的算力。
七、風險、挑戰
切換延遲:OCS 仍是毫秒等級,不適合短流逐包調度 → 實務上用 TE 把短流交給近端/間接路徑,ToE 僅針對長壽命大流與階段轉換做重構。
光干擾與回波:circulator 雙向的代價 → 在規格(RL/ER/RIN)上拉高門檻,收發器用 DSP-PAM4 + OIM做補償。ofc-2023-m2g.1
穩態以外的突發:需要定義重構節奏與觸發門檻;把 ToE 頻率控制在對營運友善、對吞吐有效的區間。
失效域設計:OCS 架上失效 → 以均勻扇出與四等分失效域確保“任何單架失效影響均分”,且保留 ≥75% 容量。3544216.3544265
開放互通:往生態系走,需更標準化的 OCS 控制介面 與多廠商互通(近年的公開研究已在驗證 SDN 控制器對開放 OCS 的可行性)。
科普說明:
當然,這套系統也不是沒有挑戰:
切換速度:OCS 需要毫秒級時間,對短小封包來說太慢,所以仍要依賴電子交換器。
光學干擾:單纖雙向會引入反射與雜訊,要靠更強大的 DSP(數位訊號處理)來修正。
故障容忍度:光交換器壞掉不能影響整個資料中心,因此要設計「失效域」來局部隔離問題。
標準化:目前 Google 自家能跑,但產業要普及,還需要開放控制協議、讓不同廠商的 OCS 能互通。
展望未來,如果能進一步縮短 OCS 切換延遲、讓控制軟體標準化,這套系統有機會成為下一代資料中心的共同基礎。
總結
Apollo/Lightwave Fabrics 的關鍵價值,不是酷炫的光學,而是把拓撲當成可調資源,讓網路升級、擴容、與 AI/ML 訓練回到可預測的工程流程上。
OCS + SDN + WDM 的組合,把功耗、成本、延遲與升級風險同時壓下來,體感是「少拉很多線、少搬很多箱」,但系統指標更好看。



留言