
ECOC 2025 技術焦點:PhotoniX AI 談 AI 計算的可擴展光互連技術
- 2025年10月1日
- 讀畢需時 3 分鐘
前言
AI 的崛起不僅推動了運算晶片的進步,也對資料中心網路提出前所未有的挑戰。GPU 叢集需要更高的頻寬、更低的延遲與更高的可靠性,這使得光學互連技術逐漸從邊緣走向核心。
在 ECOC 2025 上,PhotoniX AI 分享了他們對 可擴展光互連技術 (Scalable Optical Interconnects) 的觀察,強調 光學是 AI 工廠不可或缺的基礎,並提出 chiplet 化、模組化、彈性架構 的未來方向。
內容
1. AI 對網路的挑戰
傳統計算:以 CPU 為核心,透過 Ethernet 連接。
AI 計算:以 GPU 為核心,需同時支援:
Scale-Out:跨伺服器/機櫃連接,頻寬需求是傳統 Ethernet 的 10 倍。
Scale-Up:伺服器內部 GPU 間連接,頻寬需求是傳統 CPU bus 的 100 倍。
範例數據:
單一 GPU NIC 頻寬:800G。
NVIDIA GB200 GPU I/O 帶寬:7.2 Tbps。
👉 結論:傳統銅互連 (bus / PCB traces) 無法支撐,光學取代勢在必行。
2. 光互連的核心需求
帶寬密度:需在有限封裝空間內支持數 Tbps 級傳輸。
延遲:每公尺光纖增加 ~10 ns,需極低延遲光模組與交換器。
功耗:網路能耗應 <10% 總功耗,否則會壓縮 GPU 可用電力。
可靠性:不同於電信 20 年壽命的極端標準,資料中心需在低成本下平衡可靠性。
3. 光學 vs. 電子發展落差
過去 10 年:
光模組速率提升 20 倍。
交換機晶片容量提升 100 倍。
結果:I/O 成為系統瓶頸。
原因:光學元件製造仍以「手工組裝」為主,缺乏大規模自動化,進展慢於電子。
4. 解決方向:Chiplet 與模組化
Chiplet 概念:將光電功能拆分成可獨立運作的模組,像積木一樣拼接:
可與 GPU、CPU、Switch ASIC 共封裝 (CPO/NPO)。
也可放置在 PCB 上,形成獨立模組。
甚至可製成 pluggable optics,保持靈活性。
優勢:
3D 封裝可縮小尺寸、降低延遲。
彈性架構:可依應用調整為 CPU/MPU/GPU 專屬版本。
成本效益:透過半導體製程與自動化組裝,降低單位成本。
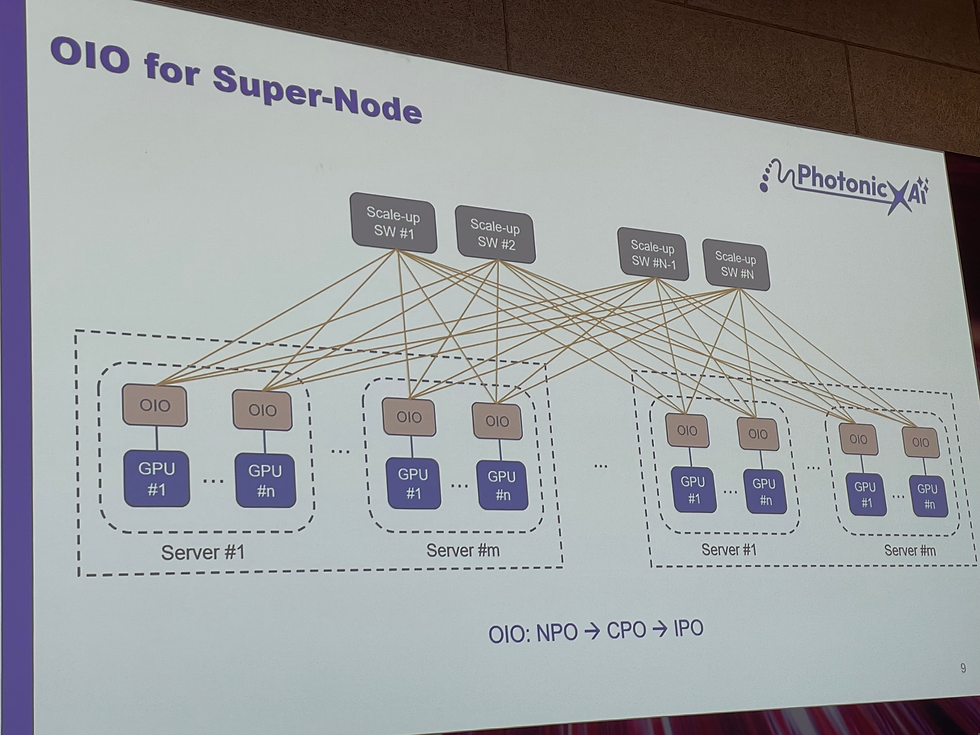
5. 應用案例:AI 超節點 (Supernode)
將 GPU 伺服器透過 Scale-Up + Scale-Out 光網路互連,使其看起來像「單一大伺服器」。
光學 IO (OIO):作為 GPU 之間的基本構件,支援超高速互連。
彈性設計:OIO 可設計為 on-board、co-packaged,或 pluggable,依客戶需求調整。
6. 技術細節與設計考量
互連材料與製程:
矽光子 (SiPh) 適合大部分場景。
若需大像素 (大核心) 則可選擇 VCSEL。
封裝形式:
高速需求 → 單片互連基板 (interposer)。
快速量產 → 傳統 PCB + SiPh 結合。
可靠性:需在低成本環境下維持足夠壽命,避免 GPU cluster 效率下降。
總結
PhotoniX AI 在 ECOC 2025 的演講傳遞了幾個關鍵訊息:
AI 讓光互連成為必須:GPU 的頻寬需求已經超越銅互連極限。
光學需更自動化:電子進展快於光學,產業需導入半導體式自動化組裝。
Chiplet 與模組化是未來方向:提供彈性、可擴展、低功耗的光互連解決方案。
應用願景是 AI 超節點:讓數百顆 GPU 透過光互連組成「單一大伺服器」。
整體來看,PhotoniX AI 提出的願景凸顯:AI 工廠時代的競爭,將取決於誰能在光學互連上實現真正的規模化、低功耗與高可靠性。
















留言