
破局 AI 算力瓶頸:透視 OCS 應用與 1.6T 時代的光通訊技術革命
- 3天前
- 讀畢需時 6 分鐘
【前言:意外的主角,重塑資料中心的「光速革命」】
在剛結束的 OFC 2026(光纖通訊大會)上,全場熱議的焦點並非只有預期中的 CPO(光電共封裝),而是原先相對小眾的 OCS(Optical Circuit Switching,光電路交換)。
這場變革的火藥味十足。根據 TrendForce 最新預估,僅 Google 代號為 Ironwood 的 TPU v7 機架部署,就將驅動超過 600 萬隻 800G 以上的高階光模塊需求。一個反直覺的真相也隨之浮出水面:當 OCS 在 Spine 層成功「取代」了傳統電交換機後,它非但沒有消滅光模塊,反而成為推動模塊規格升級的「超級推手」。
本文,我們必須深入 OCS 的物理邊界,解析它為何將 WDM 與 Circulator 成為光模塊標配,並探討未來頻寬提升的可能方案。
OCS 與傳統電交換機的本質差異:挑戰「光鏈路預算」的極限
傳統電交換機(EPS)在網路的每一次傳輸都會進行「光-電-光(O-E-O)」轉換,訊號在每個節點都會被重新生成與放大。然而,OCS 是一個純物理的「全光」設備。它只負責反射光線,不生成、不放大、也不再生訊號。
這種特性雖然省下了驚人的功耗,卻帶來了嚴峻的物理挑戰:光鏈路預算(Optical Link Budget)的急遽消耗。
OCS 內部的 MEMS 微鏡陣列在進行光束偏轉時,會產生不可避免的插入損耗(Insertion Loss)。為了在不經過放大的情況下「硬扛」這段損耗,訊號從伺服器端發出時就必須極其「強大且乾淨」。這直接影響了 OCS 專屬模塊的全面進化:從短距多模(DR)轉向單模長距(FR/LR),並強制搭載更高功率的雷射器,以確保訊號能穿透層層鏡片直達終點。
OCS 光模塊的特異化:為何 WDM 與 Circulator 缺一不可?
為了適應 OCS 的點對點全光直連架構,光模塊內部引入了兩大核心設計,這也成了 OCS 專屬模塊與一般模塊的分水嶺。

1. WDM (波分復用):壓榨單纖頻寬的極限
運作邏輯: 想像光纖是一條單線道公路。WDM 技術利用三稜鏡原理,將不同波長(顏色)的雷射信號併入同一根光纖傳輸,到終點後再解復用分開。
核心價值: 在不增加昂貴實體光纖的前提下,倍增傳輸頻寬(如 800G 甚至 1.6T)。這是應對 AI 叢集流量暴增時,成本最低、效率最高的擴容方案。
2. Circulator (光環行器):OCS 模塊的「靈魂」
傳統光模塊通常是「雙纖」設計(一發一收)。但在 OCS 架構中,單纖雙向(BiDi)傳輸是絕對剛需。
運作邏輯: Circulator 就像光訊號的「單行道圓環」。它強制光只能單向循環(Port 1 進 2 出、2 進 3 出)。這讓發射與接收信號能在同一根主光纖裡「完美會車」,互不干擾。
若缺乏 Circulator 的致命代價:
光纖數量災難性膨脹: 若維持雙纖,數萬個節點的連線會讓資料中心的光纖數量翻倍,不僅是理線噩夢,更會嚴重阻擋氣流影響散熱。
OCS 端口利用率腰斬: OCS 的微鏡端口極其昂貴。若一條連線要佔掉兩個端口(一發一收),會直接讓這台天價交換機的容量減半,這在商業決策上是不可接受的。 簡言之,沒有 Circulator,OCS 的設備成本與部署難度將直接翻倍。

邁向 1.6T 時代的頻寬之壁:IMDD 面臨物理極限
當我們試圖衝向 1.6T 甚至 3.2T 時,底層調變技術正撞上一堵「物理牆」。根據 Google 的研究,目前兩大架構:

IMDD (強度調變/直接偵測)
優勢: 架構簡單、成本極低,是目前 800G PAM4 的主流。
劣勢(致命傷): 對色散(CD)的容忍度極差。在 100G 速率下可跑 4 公里,但到了 400G 單波速率,色散會導致訊號嚴重失真,距離被腰斬至僅剩 0.25 公里,完全無法滿足資料中心規模擴展的需求。
Coherent (相干光通訊技術)
優勢: 效能怪獸。同時利用光的強度、相位與偏振來乘載資訊,並配合 DSP 進行電子色散補償(EDC),能完美抵銷物理干擾,靈敏度高出 10dB。
劣勢: 架構過於複雜,且功耗與成本極高,過去僅用於跨海纜線。
這也正是 Coherent-Lite(輕量化相干技術) 應運而生的契機:它旨在保留相干技術的優點,同時透過「減配優化」來降低功耗與成本。
什麼是 Coherent-Lite?「降維打擊」的相干技術
Coherent-Lite 是專為資料中心內部(< 2km)與校園網路(2-10km)優化的技術。它的核心哲學是:用「減法」換取商業可行性。
1. 打破物理枷鎖:為何非 Coherent-Lite 不可?
當 1.6T 的單波速率撞上色散高牆,Coherent-Lite 展現了降維打擊的優勢:

免疫色散限制: 消除 IM-DD 的痛點,允許在資料中心環境使用更高色散但低損耗的波長。
提升 10dB 靈敏度: 讓訊號跑得更遠,並降低 FEC(糾錯)負擔,達成 AI 叢集渴望的「極低延遲」。
2. 架構對決:光學做減法,晶片做加法



傳統 IM-DD 路線(如 CWDM4)需要 4 顆雷射與調變器,光學 BOM 成本隨頻寬線性成長。而 Coherent-Lite 透過偏振復用技術,僅需 1 顆雷射。它將問題從難以微縮的光學元件轉移到了受惠於摩爾定律的 DSP 晶片上。
3. 半導體經濟學:享受 CMOS 的「次線性」增長紅利

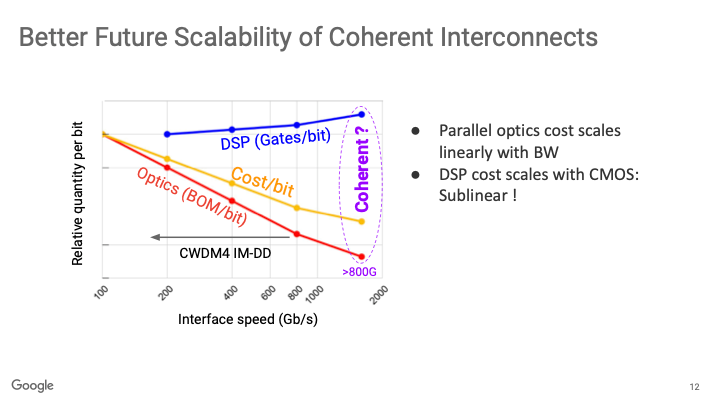
Google 的戰略很明確:「簡單的光學,配上聰明的電子」。隨著工藝進向 3nm,DSP 的成本與功耗增長速度(Sublinear)遠低於頻寬成長速度。速率越高,Coherent-Lite 的性價比就越具統治力。
4. 落地前的硬仗:類比元件與驅動電壓的挑戰

挑戰在於**「調變器效率」**。16-QAM 需要更大的驅動擺幅(Drive Swing)。


相干技術需要雙倍的驅動電壓,這在矽光子領域是個挑戰。但若能攻克高效驅動器,相干技術能獲得高達 5dB 的鏈路預算優勢,這正是克服 OCS 插入損耗的最佳利器。
5. 終極型態:專為資料中心量身定製
Coherent-Lite 為了在插槽內取代傳統模組,必須捨棄昂貴的電信思維:不需要全 C-band 可調式雷射,改用固定波長或少通道 WDM 雷射,並針對 10 公里內環境對 DSP 進行最嚴苛的功耗「瘦身」。
標準化與實戰驗證:Marvell 與 Ciena 的 Coherent-Lite 佈局
業界巨頭已經開始將 Coherent-Lite 技術落地於真實的 AI 基礎設施中。
Marvell 與 Lumentum 的 Scale-up 革命 (OFC 2026) 在 2026 年的 OFC 大會上,Marvell 與 Lumentum 展示了如何利用 OCS 構建下一代 AI 擴充基礎設施。這場演示將 Marvell 的 Aquila 1.6T Coherent-Lite DSP(專為短距 O-band 優化) 與 Lumentum 的 R300 OCS 交換機 完美結合。透過建立直接的光學路徑,避免了 OEO 轉換,該方案宣稱可減少高達 98% 的交換延遲,並在大規模 GPU 叢集中節省超過 65% 的能耗,徹底突破了傳統封包網路的「網路牆」。
Ciena 的 WaveLogic 6 Nano (WL6n) 1.6T 應用場景 光通訊大廠 Ciena 則進一步定義了 Coherent-Lite 的四大核心應用場景:
資料中心內部 1.6T 連接: 直接用於 Switch-to-Switch 連接,解決 PAM4 在 1.6T 速率下的距離與功耗瓶頸。

高密度 AI 叢集互連: 部署於後端網路(Backend Network),以更精簡的收發器數量達成 1.6T 傳輸,支撐大規模 AI 訓練的極高頻寬密度。

校園級互連 (Campus Connectivity): 針對相距 2 至 20 公里內的多個資料中心建築,提供剔除冗餘功能、低耗能的專屬互連方案。

標準插拔式演進: 提供符合 QSFP-DD 和 OSFP 標準的插拔式模組,讓雲端供應商能無縫從既有平台升級至 1.6T。

【結語:從傳輸管道到架構重塑】
光學技術正經歷一場深刻的典範轉移。從 Circulator 與 WDM 在 OCS 架構中的「神救援」,到 Coherent-Lite 對相干技術的「降維打擊」,這都不僅僅是規格的提升。
在 1.6T 時代,光學不再只是兩點之間的「傳輸管道」,它已成為 AI 算力基礎設施的核心「架構層」。透過將物理層的損耗轉交給強大的 DSP 處理,並利用 OCS 實現靈活的拓撲切換,我們正在進入一個功耗、延遲與頻寬能達成完美平衡的全光網路時代。

留言