
技術文章分析 | 矽光子微環調製器的 200Gb/s 時代:NVIDIA 的設計美學與權衡之道
- 2天前
- 讀畢需時 3 分鐘
1. 前言:為什麼微環調製器是 CPO 的天選之子?
隨著 AI 工廠規模化,傳統的可插拔光學模組在功耗與密度上已顯疲態。CPO(Co-Packaged Optics) 被視為終極解答,能提供高達 5 倍 的功耗效率提升與 10 倍 的韌性改善 。在眾多調製器方案中,MRMs 憑藉其極小的腳印(Footprint)和高頻寬密度脫穎而出,且與 CMOS 工藝高度兼容,特別適合透過 TSMC 的 COUPE(Compact Universal Photonic Engine) 等製程進行 3D 集成 。
然而,要在單路突破 200 Gb/s,設計者必須在電學頻寬、光學損耗、線性度與調製效率之間進行極其複雜的協同優化(Co-optimization)。
2. 參考來源
標題:Si Microring Resonator Modulators at >200Gb/s
作者:David Patel
單位:NVIDIA
發表平台:OFC 2026 (Optical Fiber Communication Conference)
3. 深度圖表分析
圖 1:電學模型與 3D 集成的物理極限
這張圖揭示了 MRMs 電學性能的底層邏輯:

圖 1a & 1b(電路模型與傳遞函數):
調製頻寬主要受限於 PN 結的電阻 與電容 。
若不考慮寄生參數,響應近似於單極點 RC 模型。為了突破頻寬限制,業界開始引入電學電感峰值(Inductive Peaking) 技術 。
圖 1c(效率與電容的權衡):
這是一個「苦澀」的折衷:增加摻雜濃度雖然能降低 R_j(提升頻寬),但會導致光學損耗增加,且 junction 電容 C_j 也會隨之變動 。
圖 1d(3D IC 結構):
展示了透過 TSMC COUPE/SOIC 混合鍵合技術實現的 EIC(電路晶片)與 PIC(光學晶片)堆疊 。
重要性:這種 3D 集成能極大縮短電訊號路徑,降低 RLC 寄生參數,這對於 200 Gb/s 以上的超高頻訊號至關重要 。
圖 2:光學動力學與 EO 峰值效應

MRMs 的光學響應並非線性的,且深受熱效應影響:
圖 2a(極點與零點分析):
小訊號響應由一對共軛複極點和一個零點決定 。
圖 2b(耦合狀態的影響):
展示了欠耦合(Undercoupled)與過耦合(Overcoupled)在不同偏置下的響應差異 。
在高功率下,由於光學自熱(Self-heating),調製器通常只能在諧振峰的低波長側工作 。
圖 2c(EO 峰值與失諧量 Detuning):
關鍵洞察:減小失諧量 (讓激光更靠近諧振峰)可以提高消光比(ER),但會導致頻寬下降 。
EO 峰值發生在調製邊帶與腔諧振一致時,這使得 DC OMA(光調製幅度)與頻寬無法同時達到最佳,必須尋求最佳的增益頻寬積(Gain-Bandwidth Product) 。
表 1 & 圖 3:各類 PN 結設計的華山論劍
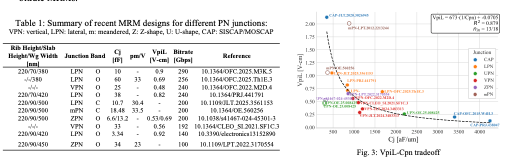
這是論文中最具參考價值的數據對比:
結結構對比:涵蓋了 LPN(側向)、VPN(垂直)、ZPN(Z型)、mPN(曲折型)以及 CAP(SISCAP/MOSCAP)等設計 。
性能數據:
目前紀錄保持者之一達到了 290 Gb/s (LPN),其 V_pi L 為 0.9 V-cm,電容僅 10 fF 。
圖 3 的分佈曲線:大多數 junction 設計都落在同一條權衡曲線上。位於左下角(低 V_pi L$ 且低 C_j)的設計代表了目前最優的技術走向 。
結論:單純追求相移效率(低 V_pi L)若是以增加損耗為代價,會被腔體增強效應的下降所抵消,因此整體的協同優化才是王道 。
4. 結論:通往 1.6 Tbps 之後的道路
NVIDIA 這篇論文清楚地告訴我們:微環調製器的未來不再是單兵作戰。
3D 集成是標配:藉由 TSMC COUPE 等製程降低寄生參數,是實現 >200 Gb/s 的物理前提 。
電子與光學協同設計:利用電感峰值、非線性等化(Non-linear Equalization)來彌補光學動態造成的非線性 。
精準建模:隨著物理機制變得複雜(如 TPA、FCA 效應),支持 Verilog-A 的精確光電熱一體化模型將成為設計師的標配工具 。
微環調製器已正式跨入單路 200G 的門檻,這將為下一代 1.6T 甚至 3.2T 的 CPO 交換機鋪平道路。



留言