
OFC2026 - CPO Integration Ready for AI Pipelines - OFC Workshop Panel- NVIDIA, Broadcom, Cisco, Oracle, Arista, AMD, Meta
- 3月16日
- 讀畢需時 6 分鐘
已更新:3月20日
前言: 在 OFC 2026 這一光通訊產業的最高殿堂上,「共封裝光學 (CPO) 是否已準備好支撐 AI 管道?」成為最具決定性的戰略命題 。回顧歷史,IBM 早在 16 年前便於 Power 775 系統中達成 CPO 的首次商業部署,並出貨約 10,000 套系統 。然而,時至今日,隨著 AI 叢集規模向 130,000 個 GPU 邁進,傳統銅線與可插拔光學模組的物理極限已迫在眉睫 。本次Workshop匯聚了 Meta、Oracle、NVIDIA、Broadcom、Arista、Cisco 與 AMD 等產業鏈巨頭,從前端的矽光子元件良率,到後端的叢集總持有成本 (TCO) 與液冷散熱,進行了史無前例的深度數據碰撞。這不僅標誌著 CPO 從「技術火力展示」正式轉入「規模化量產」的深水區,更預告了未來 12.8T 至 51.2T 網路交換節點的版圖重塑。

核心技術與數據深度解析:各廠戰略與量產實績
在此次閉門級別的工作坊中,終端使用者 (Hyperscalers) 與晶片/系統供應商展現了截然不同的技術解方與量產進度。
1. Oracle:嚴守可靠性底線,倡議插槽化與擴展束技術
Oracle 傑出工程師 Mark Filer 指出,在其 130,000 個 GPU 的超級 AI 叢集中,節點已原生配置 1.6T NIC,並採用多平面 (Multi-plane) 擴展架構 。
核心痛點與 CPO 效益: 網路中斷對於高昂的 GPU 叢集是致命的。CPO 消除了人為插拔模組導致的故障點,且相較於完全可重構系統,可節省高達 50% 的功耗與 30% 的成本 。
架構偏好 (Socketed CPO): Oracle 強烈排斥與單一交換器 ASIC 供應商綁定的垂直整合封裝 。他們提倡如 PPAK 這樣的插槽式 CPO 方案,以便於 RMA 維修與實現多供應商生態 。
光學連接器創新: 針對前面板可能高達 4096 條光纖的單點故障風險 (Blast Radius),Oracle 點名支援「擴展束技術 (Expanded Beam Technology)」,如 US Conec 的 Prism PNT 或 3M 的 EBO,這能將物理插拔力降低 20 倍,並大幅提升對粉塵的免疫力 。













2. Meta:5,000 萬裝置小時的 CPO 可靠性實測數據大公開
Meta 光學基礎設施總監 Drew Alduino 帶來了業界最渴望的實戰數據,直指 TCO 才是最終決策依據 。
加速老化測試數據 (43°C 環境):
2x400G FR4 可插拔模組: 累計 6881.48G 裝置小時,平均故障間隔時間 (MTBF) 僅為 0.7 百萬小時 。
Phase 1 CPO 系統: 達到 4000 萬等效裝置小時 。若包含可插拔雷射光源 (PLS) 內部 SMT 元件的製造瑕疵,MTBF 約為 1.7 百萬小時 。若排除該可維修故障,CPO 的 MTBF 展現出比可插拔模組高達 10 倍的提升 。
常溫部署現況: Meta 目前已有 Phase 2 的 CPO 系統在 22°C 標準環境下運行,累計達 5000 萬裝置小時,且故障率極低,目前尚難以精準計算新的 MTBF 。






3. Arista:插拔式模組的反擊,發布 12.8T XPO 液冷架構
當多數大廠看好 CPO 時,Arista 的 Vijay Vusirikala 拋出了震撼彈,宣示「插拔式模組不會消亡」 。
XPO (Extra Dense Pluggable Optics) 規格: 容量高達 12.8 Tbps (200G/lane),相當於 8 個 OSFP 模組的吞吐量 。
原生液冷 (Native Liquid Cooling) 數據: 透過直接液冷設計,組件溫度可顯著降低 20 至 25°C,配合組件數量的減少,系統級可靠性將飆升 8 倍 。
密度極限: XPO 能在 1RU 空間內實現 204.8 Tbps (原需 4RU 的 OSFP),機架密度提升 4 倍,單一機架可達 6.4 Pbps 。










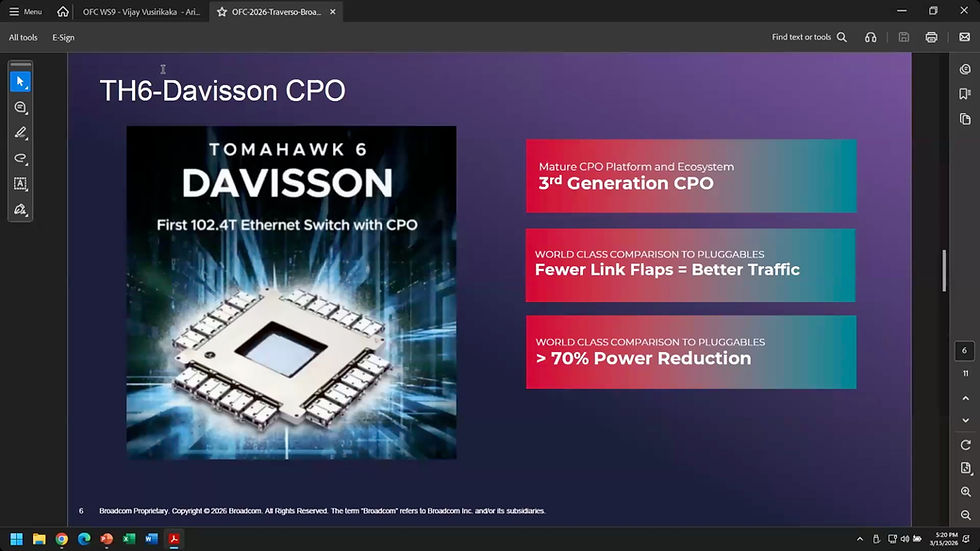
4. Broadcom:Tomahawk 6 CPO 量產與調變技術轉向
Broadcom 的 Matt Traverso 展現了其在 CPO 賽道的統治力。
Davidson 平台: 作為第三代 CPO 產品,這是首款結合 Tomahawk 6 (TH6) 核心裸晶的 100G 乙太網路 CPO 交換器 。
功耗數據: 與可插拔模組相比,實現了超過 70% 的功耗降低,並能將 Link Flap 錯誤率控制在遠低於 KP4 FEC 容忍度 (16 bit errors) 的水準 。
核心技術轉向: 宣布放棄 PAM4 調變,轉向 NRZ (或 M2) 編碼與 WDM 技術,以避免 PAM4 帶來的 4.8 dB 訊號雜訊比 (SNR) 懲罰 。






5. Cisco:良率與物理極限的冷水,「CPO 必然但非迫在眉睫」
Cisco 的 Anthony Torza 從工程物理學角度提出了務實的警告 。
訊號完整性 (SI) 極限: 在 200G 世代,0.9mm 的 BGA 間距已經大於四分之一波長,將引發嚴重的反射退化問題 。然而,Cisco 仍能利用傳統 PCB 佈線實現 64x OSFP (1600G) 的 200G/lane 交換器 。
良率噩夢 (The Yield Trap): 在一個搭載 16 個光學引擎的 CPO 系統中,即使單一引擎貼片良率達 95%,整機良率也僅剩約 44% ($0.95^{16}$) 。
散熱微觀效應: 100% 液冷系統會將氣流降至 2-3 CFM,這將從根本上消除傳統風冷帶來的灰塵累積與內部污染問題,無意間提升了現有模組的可靠性 。








6. NVIDIA:微環調變器 (MRM) 與台積電 COUPE 的商用突破
NVIDIA 的 Amir Saheki 揭示了 Scale-out (NVLink/InfiniBand) 架構下的矽光子進展 。
MRM 商用化: 首次在 Blackwell 等出貨產品中商用化微環調變器 (MRM)。儘管 MRM 對溫度極度敏感,NVIDIA 成功透過複雜的自適應電路與熱管理解決了穩定性問題 。
晶圓級封裝: 採用台積電 (TSMC) 的 COUPE 異質整合技術,整合 5nm 電子 IC (EIC) 與光子 IC (PIC) 。此製程允許在晶圓級別進行高吞吐量的光電測試 (EOE testing),大幅篩除不良品,實現 CMOS 等級的規模化降本 。









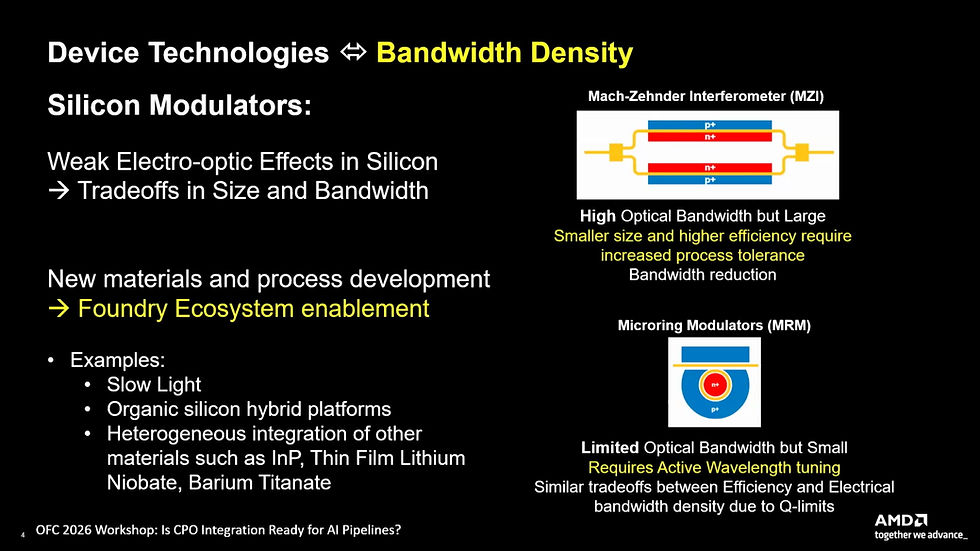
7. AMD:材料極限與介面共識
AMD 的 Juthika Basak 強調,CPO 帶來了 3 倍的能源效率提升 。
調變器瓶頸: 由於純矽缺乏強烈的電光效應,無論使用 MZI 或 MRM,都必須在尺寸與頻寬之間妥協,呼籲晶圓廠生態系引入新材料製程 。
耦合取捨: 邊緣耦合 (Edge Couplers) 對光學組裝的公差要求極高,而光柵耦合 (Grating Couplers) 則依賴晶圓廠的製程公差,這需要 OSAT 與 Foundry 的緊密協同 。





共識與分歧點深度剖析
絕對共識 1:TCO 與 RAS 決定一切。 所有的功耗降低 (降低 50-70%) 最終都是為了將電力還給 GPU,以提升 AI 代幣生成量 (Tokens/watt) 。可靠性 (Reliability)、可用性 (Availability) 與可維修性 (Serviceability) 是准入 AI 叢集的最低門檻 。
絕對共識 2:外部雷射 (ELS) 的必要性。 考量到雷射是主要熱源與潛在衰減元件,將高功率雷射以可熱插拔模組 (如 PLS) 的形式從 CPO 封裝中獨立出來,已成為各廠縮小「爆炸半徑」(Blast Radius) 的標準做法 。
戰略分歧 1:224G 世代的過渡路徑。 Oracle 與 Broadcom 認為 224G/lane 已是 CPO 的成熟切入點 ;Arista 則試圖用 12.8T XPO 液冷插拔模組截胡 ;Cisco 則堅稱 400G/lane 才是 CPO 技術發揮絕對優勢的「技術必然」(Technical Imperative) 。
戰略分歧 2:封裝型態 (Soldered vs. Socketed)。 晶片供應商傾向於直接焊死的 CPO 以優化訊號與封裝成本;而終端雲端巨頭 (如 Oracle) 則強烈要求 Socketed (插槽化) 或 NPO 架構,以確保多供應商貨源並降低單板報廢風險 。
產業鏈與市場影響
OSAT 與 Foundry 的價值重分配: NVIDIA 採用 TSMC COUPE 技術證明了 2.5D/3D 異質整合 (如混合鍵合 Hybrid Bonding) 已成為光電整合的終極解方 。無法提供次微米級 (Submicron) 光學對準與高吞吐量晶圓級 EOE 測試的封測廠,將被淘汰出局 。
標準化聯盟的勢力劃分: OCI MSA (NVIDIA, AMD, Broadcom, Meta 等) 正強勢主導 Scale-up (節點向上擴展) 的光學規範 ;而在 Scale-out (向外擴充) 端,XPO 等新型插拔規格將與早期 CPO 方案形成激烈定價戰 。
光學連接器大洗牌: 隨著光纖數量呈指數上升,傳統的 MPO 物理接觸連接器已不敷使用,擴展束 (Expanded Beam) 與非接觸式光學連接器將迎來爆發性成長 。
Simple Tech Trend 主筆觀點
作為緊盯矽光子與高速網路基礎設施演進的觀察者,本次 OFC 2026 讓我們看到 CPO 從「科學實驗」真正跨越到了「工程良率與供應鏈管理」的殘酷現實。
我們預判,在未來 12 到 24 個月內:
「雙軌並行」將是常態: 裝配原生液冷的超高密度插拔模組 (如 Arista 倡議的 XPO) 將在 224G/lane 世代吃下大量因 CPO 供應鏈良率爬坡不及而溢出的訂單 。
CPO 的黃金交叉落在 400G/lane: 當電氣走線的物理極限徹底封死 PCB 路由時,擁有 70% 功耗優勢的 CPO 將在 2027 年後迎來爆發 。
生態系的收斂: 唯有具備台積電等頂尖 Foundry 支援、能解決 16 顆光引擎同步貼片良率挑戰的 Fabless 巨頭,才能最終主導這場 130k GPU 互連的世紀之戰 。



留言